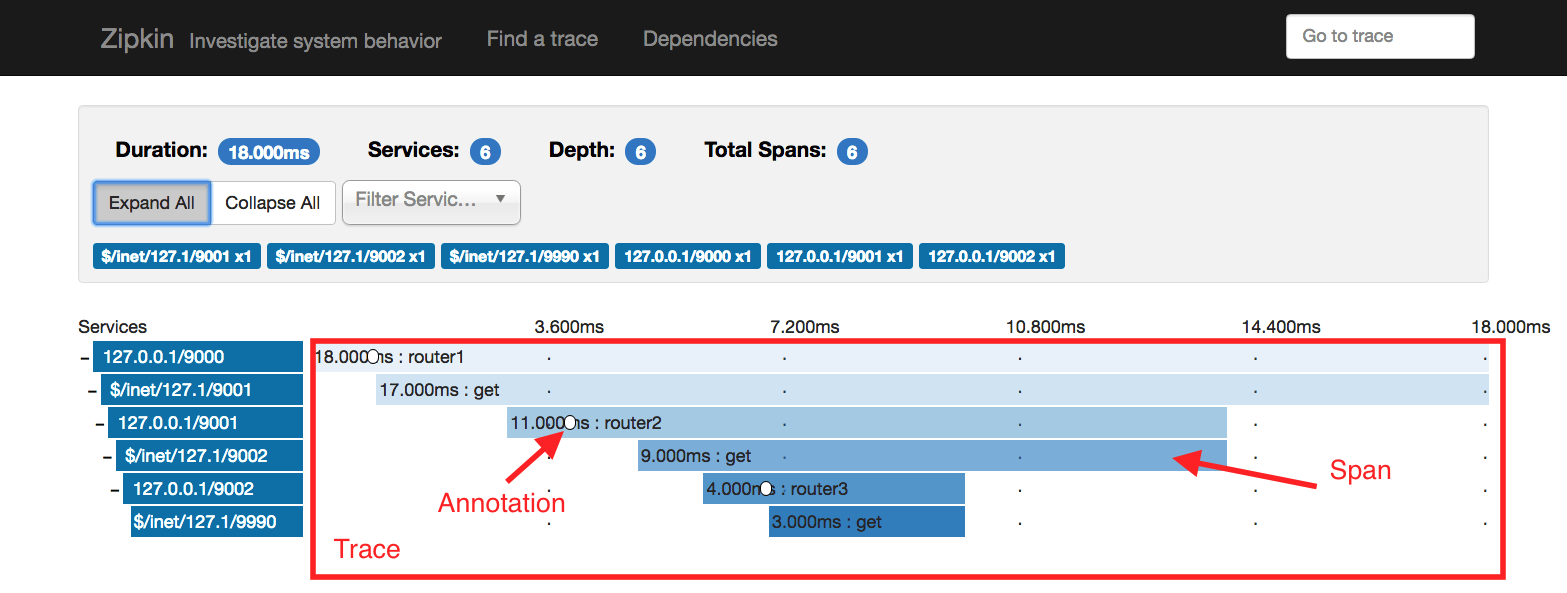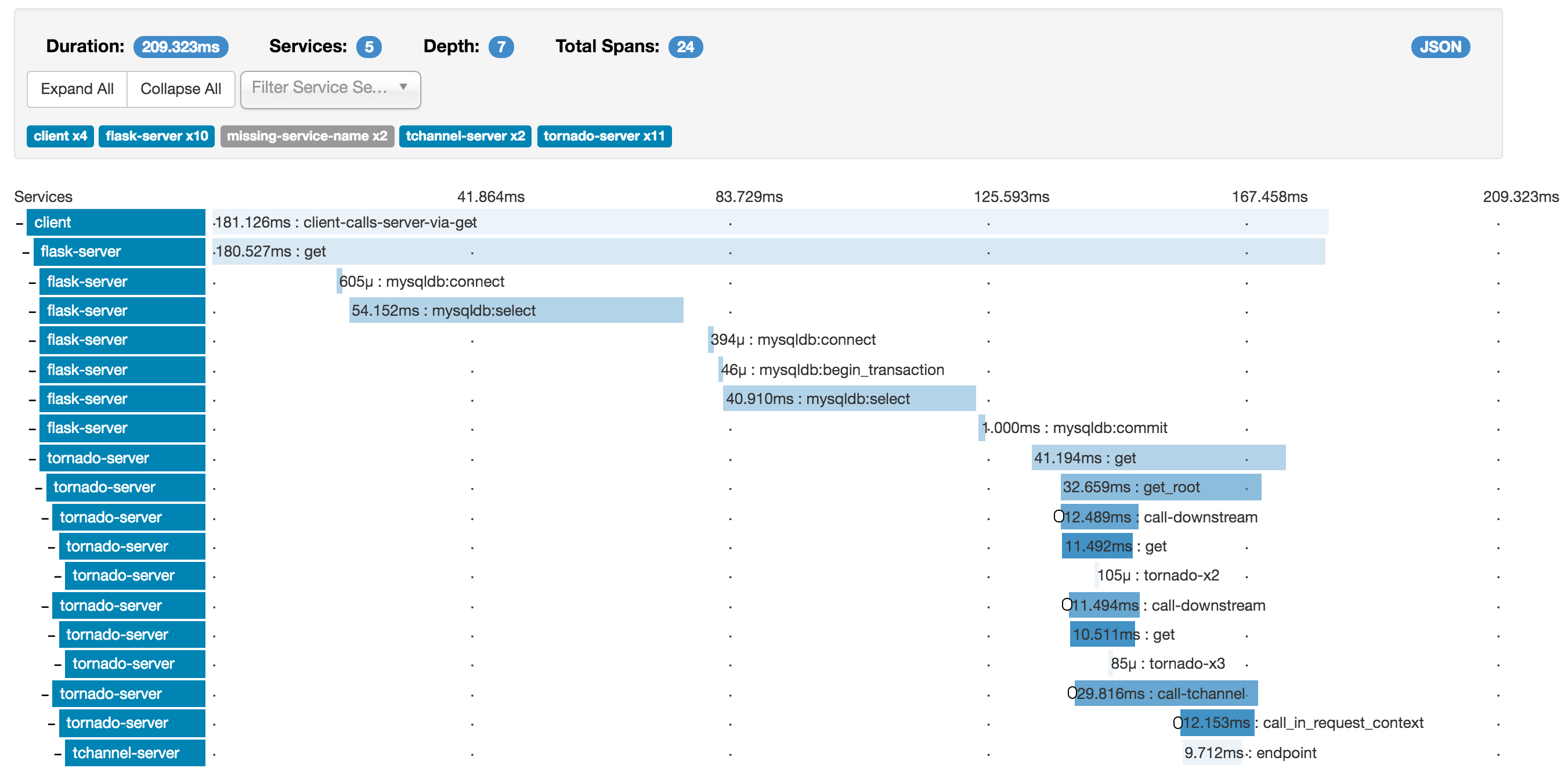
Here we introduce the design of Dapper, Google’s production distributed systems tracing infrastructure, and describe how our design goals of low overhead, application-level transparency, and ubiquitous deployment on a very large scale system were met. Dapper shares conceptual similarities with other tracing systems, particularly Magpie [3] and X-Trace [12], but certain design choices were made that have been key to its success in our environment, such as the use of sampling and restricting the instrumentation to a rather small number of common libraries.
The main goal of this paper is to report on our experience building, deploying and using the system for over two years, since Dapper’s foremost measure of success has been its usefulness to developer and operations teams. Dapper began as a self-contained tracing tool but evolved into a monitoring platform which has enabled the creation of many different tools, some of which were not anticipated by its designers. We describe a few of the analysis tools that have been built using Dapper, share statistics about its usage within Google, present some example use cases, and discuss lessons learned so far.